The Oracle and the Firm
Like most of the internet, I've been diving into Fable 5 over the last 24h. And like most of the internet, I've been pretty blown away with the quality.
But as I've been using both Fable and GPT-5.5, I couldn't help but notice there are clear differences in approach which make the two models behave quite differently. And we're seeing two very different training regimes play out.
For any frontier model, accomplishing real work is an exercise in context management. The model needs to solve a problem across a very large number of tokens; some are explored via tool calls, others are the model thinking. Then it needs to produce a result.
To get models to solve harder and harder tasks that run for increasing amounts of time, you need to figure out how to scale that context management.
OpenAI: the oracle
Since roughly ChatGPT 5.3-Codex, I've noticed that the model has improved a lot at dealing with long context windows. It stays coherent even across long-running tasks or /goal implementations, despite having a smaller context window than the corresponding Opus models (~200k vs 1m).
The approach Codex takes is compaction, and there are two naive approaches you can use:
- you have a separate (sometimes smaller) model output a new message based upon the trajectory.
- e.g. ask 5.5 to summarize everything in the thread up to 1k tokens
- you remove certain categories of calls from the conversation.
- e.g. remove all tool calls, then begin inference
You might even imagine doing this in parallel: compacting up to a certain number of messages in a thread, and then leaving more recent ones in full fidelity.
Since earlier this year, Codex has shipped native server-side compaction built into the responses API. When the produced tokens start to overflow the context window, Codex can run a process to compact everything and retain only the relevant information.
Given that the compaction happens server side, it has two nice properties: a) OpenAI can change the implementation easily and at will without affecting clients and b) the API can take advantage of much better K/V caching for long-running threads by routing to the right GPU.
The net result, I think about like an 'Oracle'. Codex typically keeps one long thread going with frequent compactions. You will see sub-agents which execute on clean paths, but it tends to happen less often, unless nudged by the user.
Because the single thread is managing everything related to user responses, it maintains a lot of coherence. Small details which are relevant to the overall trajectory are remembered.
Anthropic: the firm
Compaction is just one way of dealing with context windows. The other approach you could take is splitting context windows across various agents. In this technique, you split the problem into various sub-problems, then have each agent execute on the sub-problem within it's own context window.
Since at least Opus 4.1, I've noticed Claude Code will eagerly take this approach. For any research of the codebase, the model will invoke Explore sub-agents which leverage Haiku to create a quick summary.
And when running Fable 5, it goes nuts.
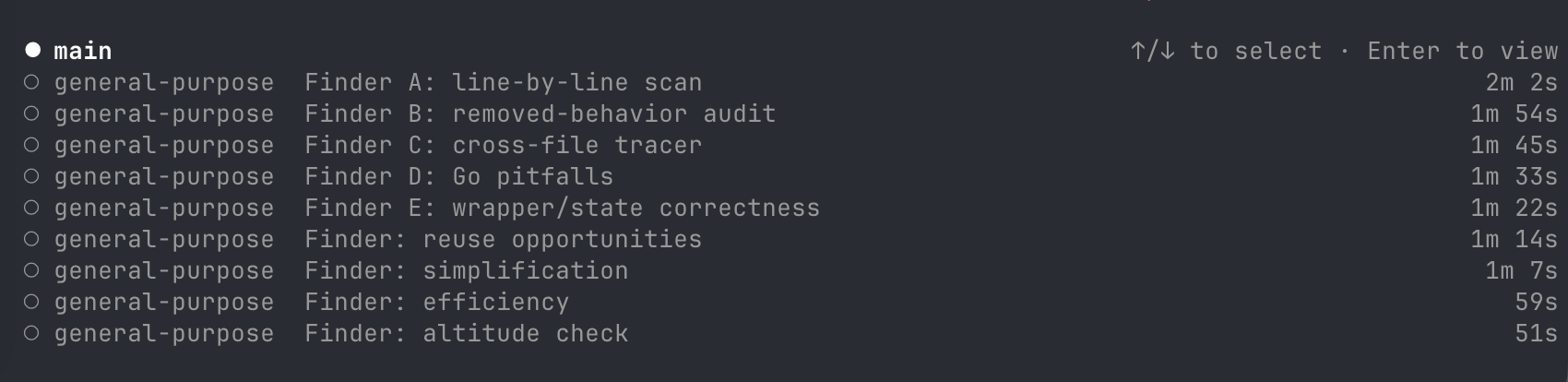
This is very different approach: sub-agents are now able to do large amounts of work within a context window, and then pass back only the relevant information to the parent agent.
In effect, this looks more like the way human organizations run. Everyone has their set of goals and inputs and outputs. They see some subset of the total information available, and make decisions based upon that. And we all communicate via language. But we don't get to see the hidden state in one another's heads.
Claude models also compact, and it takes advantage of a few of these different approaches. But the compaction is slow and requires users to upgrade the client consistently, so I assume the training regime has leaned more on delegating to sub-agents.
Takeaways
Cost and token efficiency: I suspect that Anthropic models tend to cost more because the sub-agents often end up doing duplicate work. They may be searching similar files because they aren't actively communicating.
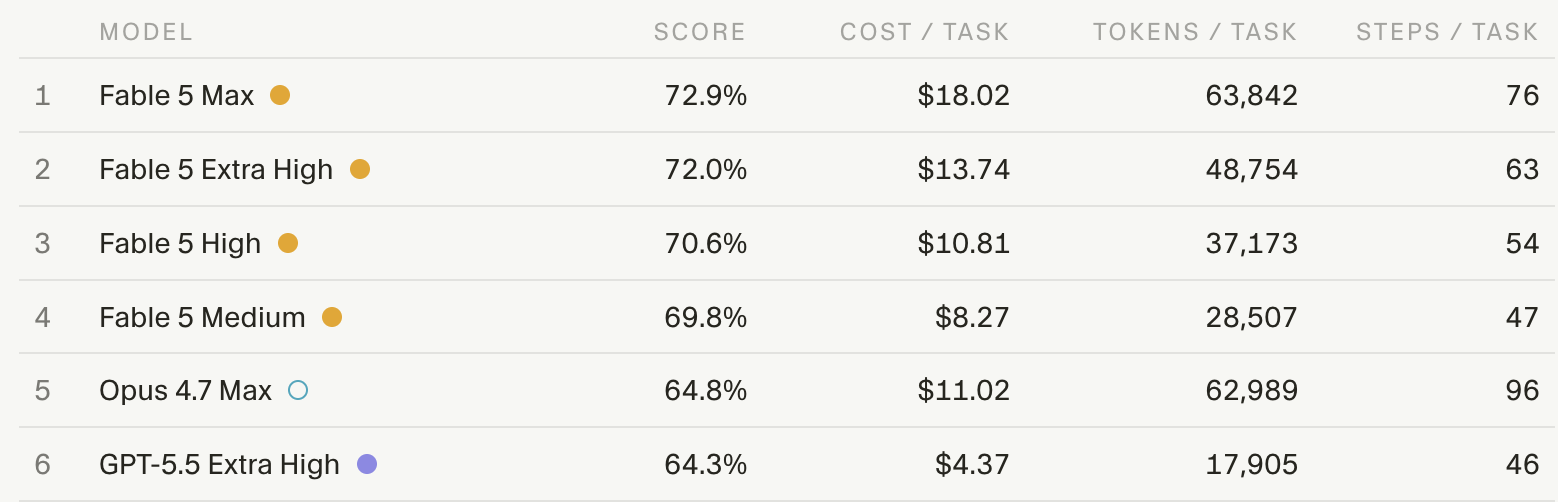
Perceived speed: Anthropic models will often seem to be "doing more", because the tokens are being produced in parallel vs serial. Many more tokens are produced during that time.
'Forgetting': a friend pointed me to some cases where Anthropic models seem less coherent, or more often tend to misreport facts to the user. I think this is true, and it's easily explained with the message-passing approach taken by sub-agents. If a sub-agent deemed a fact was not worth reporting back to the parent agent, then it will be missing from the context. In this way, the Anthropic models can more easily 'miss' obvious facts, even if it seemed like they at one point had done the research. This can happen with compaction too, but it's less likely, because the model is doing 'less work' to omit or preserve tokens.
In the end state, I expect we will see both approaches combined. Anthropic will improve their compaction (which right now is too lossy), and OpenAI will train for multi-agent setups.